Machine Learning
WAT IS MACHINE LEARNING?
Een veelgebruikte, formele definitie van machine learning is een techniek waarbij
“Een computerprogramma zou kunnen leren van gebeurtenis E, ten opzichte van soortgelijke taken T en prestatiemaatstaf P, als zijn prestatie op de taken in T, zoals gemeten door P, verbeterd door ervaring E.”
Machinaal leren omvat, kortgezegd, computer algoritmes die gebruikt worden om autonoom, dus zonder begeleiding, te leren van data en input. Hierbij hoeven computers dus niet zelf geprogrammeerd te worden, maar kunnen zelfstandig hun algoritmes veranderen en verbeteren.

Vandaag de dag wordt algoritmes voor machinaal leren gebruikt om, onder meer, computers met mensen te laten communiceren, zelfrijdende auto’s mogelijk te maken, verslagen en statistieken van sportwedstrijden te schrijven en publiceren, e-mails te controleren op spamberichten, tijdig zieke patiënten te diagnosticeren, en mogelijke terroristen te herkennen en lokaliseren.
Nagenoeg iedere industrie zal te maken krijgen met machinaal leren, en direct de positieve gevolgen ervan achterhalen.
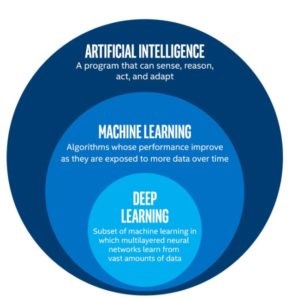
DE ROL VAN MACHINE LEARNING
Al aan het begin van de artificial intelligence hype beseften een aantal onderzoekers het belang van machines die zelfstandig kunnen leren van data – wat tot nu toe een van de hoekstenen van AI is gebleken.
Het onderzoek naar neurale netwerken, statistiek en kansberekening als onderdeel van intelligentie heeft tot nu toe tot enorme vooruitgangen in het veld geleid.
Na verloop van tijd begonnen de wegen van machine learning en artificial intelligence langzaam te scheiden. De toenemende focus op een aanpak die leunt op een op logica en kennis-gebaseerd model, drukte het kansberekening model steeds verder naar de achtergrond en daarmee de rol van machinaal leren.
Kansberekening heeft immers flink te kampen met een gebrek aan vertrouwen. Praktische problemen zoals het vergaren van de juiste data en de juiste verwerking hiervan leidden tot een forse daling in het gebruik van statistiek-modellen.
Op dat moment bewoog machine learning weg van kunstmatige intelligentie, en meer richting programmering van afleidende logica-systemen en systemen voor kansberekening en statistiek: ideaal voor oplossingen voor de opvraging van informatie en patroonherkenning.
‘Intelligente’ algoritmes zijn in staat om van enorme hoeveelheden input te leren – en dit om te zetten naar praktische output, al dan niet naar aanleiding van een nieuwe specifieke dataset die verbonden moet worden aan een bepaalde output.
Dergelijke algoritmes kunnen zo uiteindelijk voorspellingen doen of beslissingen nemen, gebaseerd op de verzamelde data en de analyse hiervan.
Zoals de eerdergenoemde voorbeelden van implementaties van machinaal leren al aantonen, is het dus op zijn waardevolst voor toepassingen waarvoor het handmatige ontwerpen en programmeren van expliciete algoritmes ontzettend lastig of zelfs onmogelijk is.
VAN THEORIE NAAR WERKELIJKHEID
Arthur Samuel, een werknemer van IBM, is degene die de term machine learning introduceerde: dit was in 1959.

Hij werd als werknemer van zijn bedrijf gezien als een autoriteit en pionier op het gebied van gaming en kunstmatige intelligentie. Hij gebruikte hier een schaakspel voor, dat steeds slimmer werd al naar gelang het meer speelde. Het onthield winnende zetten en gebruikte deze in zijn eigen partijen.
Dit was het begin van de uitwerking van het concept van machine learning in het algemeen, en van de schaakcomputer in het bijzonder: het wordt dan ook regelmatig aangemerkt als zijnde de grootvader van Deep Blue, de IBM-computer die in 1997 schaakkampioen Garri Kasparov versloeg.
Na Samuel volgden nog veel innovaties die allen verder gingen op het vinden van algoritmes die zichzelf leren, aan de hand van de verzamelde data, en aan de hand daarvan in staat zijn tot zelfstandige besluitvorming.
Ook noemenswaardig is het project van studenten van Stanford University in 1979, die tot de ontwikkeling van de zogenaamde ‘
Stanford Cart’ leidde: een bewegende robot die in staat was om zelfstandig door een kamer te bewegen en onderweg obstakels te ontwijken. Een verre voorvader van de zelfrijdende auto en robo-stofzuigers, dus.
SOORTEN ‘LEARNING’ BINNEN MACHINE LEARNING
Een computer kan op verschillende manieren leren. Dergelijke slimme algoritmes kunnen ingedeeld worden in een aantal bredere categorieën, gebaseerd op de manier waarop deze leren. Dit omvat de volgende leermethodes:
- Gecontroleerd leren, waarbij het algoritme voorbeelden van gangbare input en de daarbij passende output voor zich krijgt. Aan de hand van deze voorbeelden leert het systeem hoe bepaalde eigenschappen van de input bepalen wat de output gaat zijn. Na de initiële leerfase kan zo’n algoritme zelfstandig nieuwe input omzetten in de juiste output, of worden er oefeningen uitgevoerd waarbij bepaalde inputelementen ingedeeld moeten worden in groepen.
- Ongecontroleerd leren, waarbij geen voorbeelden gegeven worden van gangbare input en de gewenste output; maar het system zelf leert, aan de hand van de structuur van de input – bijvoorbeeld door input onder te verdelen in soortgelijke groepen.
- Semigecontroleerd leren bevat zowel elementen van gecontroleerd en ongecontroleerd leren. Na een incomplete ‘leersessie’ via de gecontroleerde methode, leert het system verder via ongecontroleerd leren.
- Ondersteund leren leert zichzelf gedrag aan, aan de hand van zijn relatie tot de rest van de wereld en behaalde successen. Het systeem leert dus al doende, bijvoorbeeld door het rijden in een voertuig of het spelen van een bepaald spel.
- Transductieleren wordt het minst gebruikt van alle methoden, en kan alleen getraind worden voor een beperkte set gevallen (gebaseerd op een budget), waarbij zelfstandig een keuze gemaakt dient te worden tussen gevallen waar in getraind moet worden.
- Deep learning gebruikt de input als basis voor het begrijpen van ‘de wereld’ en het ontwikkelen van concepten. Bijvoorbeeld voor het herkennen van vormen, of een dier: heeft het rechte zijden? Hoeveel? Heeft het ogen, oren, welke vorm? Aan de hand van dergelijke input wordt met deep learning geleerd om concepten te herkennen en te reflecteren – na opname van nieuwe data – op nieuwe concepten.
TOEPASSINGEN VAN MACHINE LEARNING
Enkele van de meest gebruikte toepassingen van de machine learning technologie zijn voor taken die nagenoeg altijd identiek zijn in uitvoering, herhalend werk dus, waarbij slechts een beperkt aantal uitkomsten mogelijk zijn.

Aan de hand van variabelen in de input, kan een systeem zichzelf constant verder ontwikkelen om nog beter zijn taak te kunnen uitvoeren – en betrouwbare output te kunnen leveren.
Een aantal concrete velden waarin al gebruik wordt gemaakt van machine learning zijn onder meer:
- Bio-informatica, waarmee onder meer eiwitfuncties voorspeld kunnen worden.
- Zelfrijdende voertuigen, die geheel autonoom van punt A naar B kan, onderweg rekening houdend met alle variabelen – zoals over verkeer, omstandigheden, obstakels, verkeersregels, etc.

- Zelfrijdende voertuigen, die geheel autonoom van punt A naar B kan, onderweg rekening houdend met alle variabelen – zoals over verkeer, omstandigheden, obstakels, verkeersregels, etc.
- Natuurlijke taalverwerking, zodat bijvoorbeeld de functie en betekenis van woorden in een zin bepaald kunnen worden en effectievere vertaal- en schrijfprogramma’s ontworpen kunnen worden.
- Audiovisuele dataverwerking, waarbij visuele weergaves en/of audiofragmenten – bijvoorbeeld captchas – geanalyseerd kunnen worden; en nadat herkenning heeft plaatsgevonden, een output geleverd kan worden die overeenkomt met de audiovisuele data.
- Gezichts- en stemherkenning, die, evenals bovengenoemd voorbeeld, aan de hand van visuele of audio-input bepaalde kenmerken opslaan en dit matchen aan bijpassende output. Een gezichtsherkenningssysteem is hier een uitstekend voorbeeld van, waarbij input van talloze bewakingscamera’s uitgelezen kan worden om gelijkende matches te vinden met een vooraf opgegeven profiel.
- E-mail spamfilters, waarbij een systeem zichzelf leert welke e-mailberichten potentieel ongewenst en/of spam zijn.
- Sportanalyses, waarbij het systeem de rol van een verslaggever of puntenteller overneemt en aan de hand van input – in de vorm van meetbare gebeurtenissen op het sportveld – output leveren in de vorm van een geschreven en gepubliceerd wedstrijdverslag.
In theorie zou dus iedere industrie die baat heeft bij een versimpeling van moeilijk te automatiseren repeterende taken, machine learning kunnen gebruiken.
Een algoritme kan de vaak subjectieve en/of aan meerdere variabelen onderhevige input classificeren in bruikbare output, wat een enorme tijdswinst zou opleveren.
Deepdream van Google
Google kan niet ontbreken bij de voorbeelden van machine learning. Google heeft het programma DeepDream. Deepdream is een neuraal netwerk dat patronen zoekt en herkent in foto’s van mensen en dieren.
Door te trainen met miljoenen afbeeldingen van gebruikers herkent de software dieren, gezichtsuitdrukkingen van mensen en locaties. Deze informatie wordt dan weer gebruikt in de ‘Photos’ app van Google. Wanneer er foto’s naar deze app geupload worden zal deze suggesties geven voor fotoalbums en filters voor bepaalde foto’s.
Facebook en DeepText
Ook Facebook kan niet ontbreken in de lijst met bedrijven die aan machine learning doet. Een van de voorbeelden van machine learning bij Facebook is het systeem DeepText.
DeepText is een algoritme wat berichten herkent en ‘begrijpt’. Een voorbeeld hiervan is wanneer jij tegen een vriend(in) via de Facebook messenger vraagt of hij/zij ook zin heeft in afhaalpizza
Facebook direct advertenties laat zien van aanbieders van thuisbezorg pizza’s.
DeepText is continue in ontwikkeling, momenteel kan het systeem in tientallen talen berichten herkennen en interpreteren. Hoe meer berichten DeepText analyseert hoe slimmer het systeem wordt. Dit geld overigens voor alle voorbeelden van machine learning.
Scania’s logistieke systeem
De truckfabrikant Scania staat ook niet stil op het gebied van machine learning. Zij hebben een systeem ontwikkeld dat met nauwkeurigheid kan voorspellen wanneer er een truck kapot gaat.
Dit geeft enorm veel voordelen met betrekking tot logistieke planning. Wanneer er een lange rit voor de boeg staat is het soms beter een bepaalde truck niet te sturen. Naast dat dit voordelen oplevert gaat het systeem nog verder.
Mocht een truck kapot gaan analyseert deze zelf of het goedkoper is om een snelle reparatie te doen langs de snelweg zodat de lading alsnog op tijd is óf te laat te komen en de kosten hiervan voor lief te nemen.
Ook hier geldt: hoe meer data en hoe vaker de analyse gedaan wordt hoe nauwkeuriger er een voorspelling gedaan kan worden.
Lees ook:
- Video Elon Musk: Totally boring company
- 9 technologische toepassingen in 2019
- Digitalisering en de Belgische arbeidsmarkt
Ben jij op zoek naar een job in deze sector? Neem contact met ons op! We helpen je graag verder.
Hoe je met onze aanpak jouw doelstellingen kan bereiken?